Motivation
Der Umgang mit digitalen Forschungsdaten und Forschungssoftware spielt in allen Anwendungsbereichen der Natur- und Ingenieurwissenschaften eine immer wichtigere Rolle. Der Grund dafür ist vor allem die wachsende Menge an Daten, die aus Experimenten und Simulationen gewonnen werden. Ohne geeignete Analysemethoden sind die ständig wachsenden Datenmengen nicht mehr sinnvoll nutzbar. Dies gilt insbesondere für die Materialwissenschaften, da die Erforschung neuer Materialien immer komplexer wird. Daher ist eine konkrete Infrastruktur für das Daten-und Softwaremanagement erforderlich, die speziell an die Bedürfnisse der Computerwissenschaften angepasst ist und sowohl zentral und dezentral als auch intern und öffentlich ohne große Hürden genutzt werden kann. Diese Infrastruktur soll den Forscherinnen und Forschern während des gesamten Forschungsprozesses von der Erstellung oder Nutzung der Simulationssoftware, über die strukturierte Speicherung und den Austausch von Daten zur Datenanalyse, bis hin zur Veröffentlichung der Daten unterstützen.
Ziel
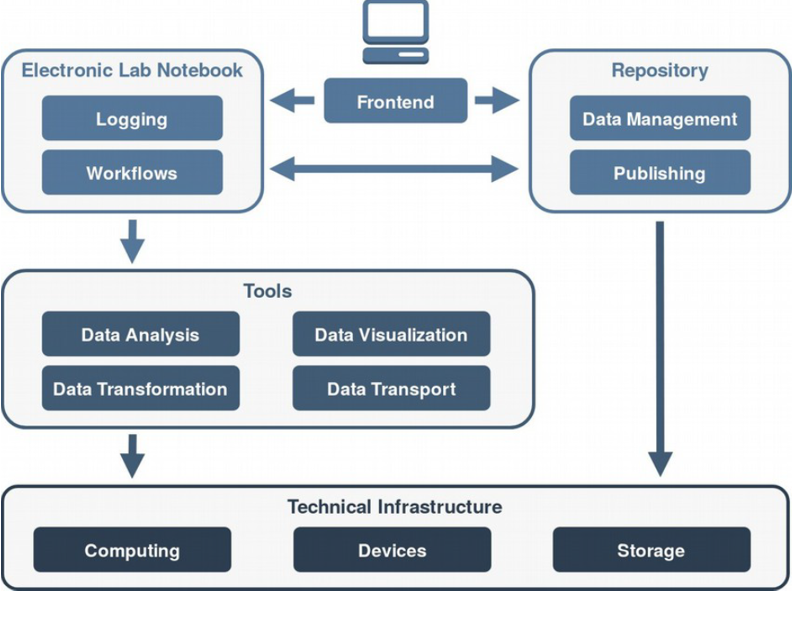
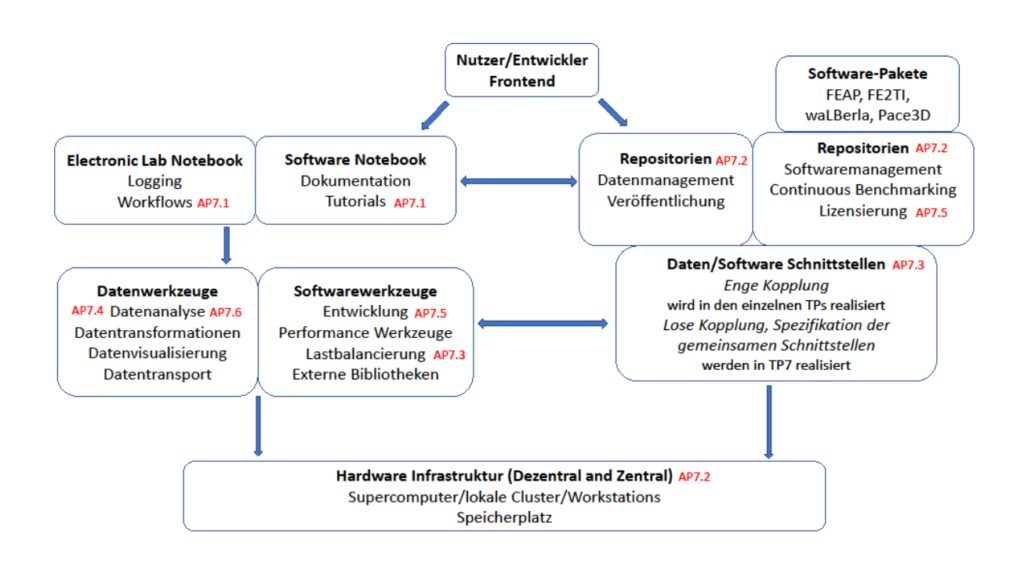
Hauptziel des Teilprojektes 7 (TP7) ist die Bündelung und Koordination der Kompetenzen in den Bereichen des HPC Software Engineering, der nachhaltigen Datenhaltung und der effizienten Datenanalyse. Aus den in diesem Bereich bereits existierenden Insellösungen der Projektpartner soll im TP7 eine gemeinsame Infrastruktur zur effizienten Auswertung und zur nachhaltigen Handhabung von großen Datenmengen und Software im Bereich des wissenschaftlichen Rechnens geschaffen werden, die auch standortübergreifend nutzbar und an die speziellen Bedürfnisse der Forschungsgruppe angepasst ist. Dadurch soll
- die Software-Interoperabilität zwischen den Teilprojekten hergestellt werden,
- die Nachhaltigkeit der Software gewährleistet werden,
- die Skalierbarkeit und Performanz gesichert werden und
- die Portabilität auf neue Rechnerarchitekturen ermöglicht werden.
Hierzu werden zum einen Methoden und Schnittstellen für den Austausch multiphysikalischer Felder über mehrere Skalen hinweg, die Ableitung von Randbedingungen und effektiven Kenngrößen daraus sowie die einheitliche In-situ-Auswertung von Experimenten und Simulationen entwickelt und implementiert. Zum anderen werden auch Techniken und Ansätze zur kurz- und mittelfristigen Speicherung von Daten und Software im Arbeitsablauf sowie der langfristigen Archivierung von Daten und Software zur Veröffentlichung und nachhaltigen Nutzung von Projektergebnissen untersucht und umgesetzt.
Ein weiterer Teil der zu schaffenden Infrastruktur ist ein gemeinsames Software-Repository für die Continuous-Integration- und Continuous-Benchmarking-Entwicklung auf verschiedenen Plattformen und Hochleistungsrechnern. Zudem soll teilprojektübergreifend Know-How für die Entwicklung funktionaler und nicht funktionaler Tests der Software eingebracht werden. Weiterhin soll die Allokation von Rechenressourcen zentral koordiniert und gemeinsam genutzte Software in einem einheitlichem Rahmen verfügbar gemacht werden, um z. B. Konflikte zwischen unterschiedlichen Versionen gemeinsam genutzter Software zu vermeiden.
Vorgehensweise
Das Arbeitsprogramm sieht 6 Forschungsphasen vor. In der ersten Phase erfolgt die Festlegung gemeinsamer Standards für Software, Dokumentation und allgemeine Datenschnittstellen. In der zweiten Phase wird die technische Infrastruktur geschaffen. In Phase 3 werden Numerische Daten- und Softwareschnittstellen zur Übertragung experimenteller Daten zwischen den Teilprojekten umgesetzt. In-Situ-Analyseroutinen werden in Phase 4 erstellt. In der darauf folgenden Phase 5 werden eine kontinuierliche Integration und kontinuierliches Benchmarking durchgeführt und in der Phase 6 folgt die Entwicklung von Datenanalysemethoden für den Einsatz in allen Teilprojekten.
Teilprojektleitung

Prof. Dr. rer. nat. Britta Nestler
Hochschule Karlsruhe – Technik und Wirtschaft (HsKA)
Institut für Digitale Materialforschung (IDM)
- E-Mail: britta.nestler@kit.edu

Dr.-Ing. Michael Selzer
Hochschule Karlsruhe – Technik und Wirtschaft (HsKA)
Institut für Digitale Materialforschung (IDM)
- E-Mail: michael.selzer@kit.edu

Prof. Dr.-Ing. Harald Köstler
Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU)
Lehrstuhl für Informatik 10 (Systemsimulation) (LSS)

Prof. Dr. rer. nat. Ulrich Rüde
Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU)
Lehrstuhl für Informatik 10 (Systemsimulation) (LSS)
- E-Mail: ulrich.ruede@fau.de
Teilprojektbearbeitung

Christoph Alt, M.Sc.
Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU)
Lehrstuhl für Informatik 10 (Systemsimulation) (LSS)
- E-Mail: christoph.alt@fau.de